はじめに
HTTPサーバーからのデータのダウンロード
HTTPリクエスト処理
プロキシサーバー経由でのWebリクエストの送信
HEADリクエストでWebページが存在するかどうかを確認する
クライアントコードでのMozilla Firefoxのスプーフィング
HTTP圧縮によるWebリクエストの帯域幅の節約
CGIを使用した(Pythonベースの)Webサーバーのゲストブックの作成
レポート
この授業では、いくつかのサードパーティライブラリを含むPython HTTPネットワークライブラリ関数について説明します。 たとえば、requestライブラリはHTTP要求をより適切でクリーンな方法で処理します。
POSTを使用したWebフォームの送信、ヘッダー情報の操作、圧縮の使用など、多くの一般的なHTTPプロトコル機能がいくつかのコードに示されています。CGIを備えたWebサーバーは、Webアプリケーションでゲストコメントフォームを作成するなど、基本的なCGIアクションも示します。
この実験はWindowsでもLinuxでも実施できます。WindowsにPythonをインストールしていない人はここからインストールして下さい。また、Windowsでエディタをインストールしていない人は、例えば、Sublimeを使って下さい。或いは、アナコンダをインストールして、付属するエディタ(Spyder等)を使ってください。
また、この実験で使用する全てのPythonとHTMLコードはここをクリックしてください。
HTTPプロトコルを使用して任意のWebサーバーからデータをフェッチする単純なHTTPクライアントを作成したいとします。 これは、独自のHTTPブラウザーを作成するための最初のステップです。
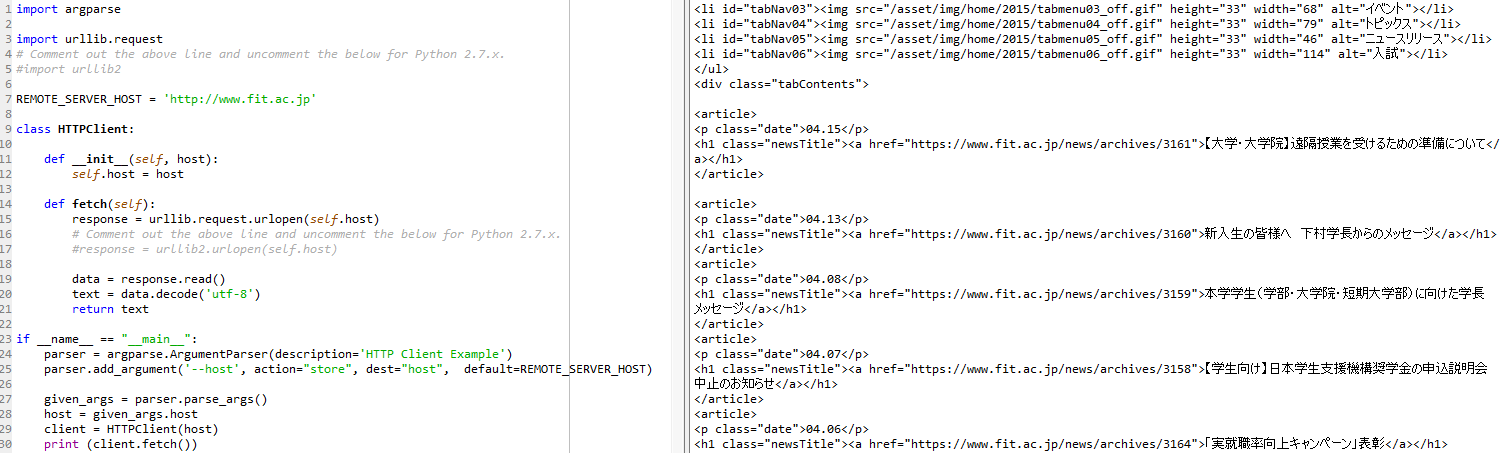
以下は、単純なHTTPクライアントのコード(download_data.py)です。
このコードは、リモートホストからデータを取出すurllib.requestモジュールを使います。 urllib.request.urlopen()は、指定されたWebページを開いてデータをフェッチします。
Webサーバー(simple_http_server.py)を作成します。 Webサーバーはクライアント要求を処理し、単純なhelloメッセージを送信します。
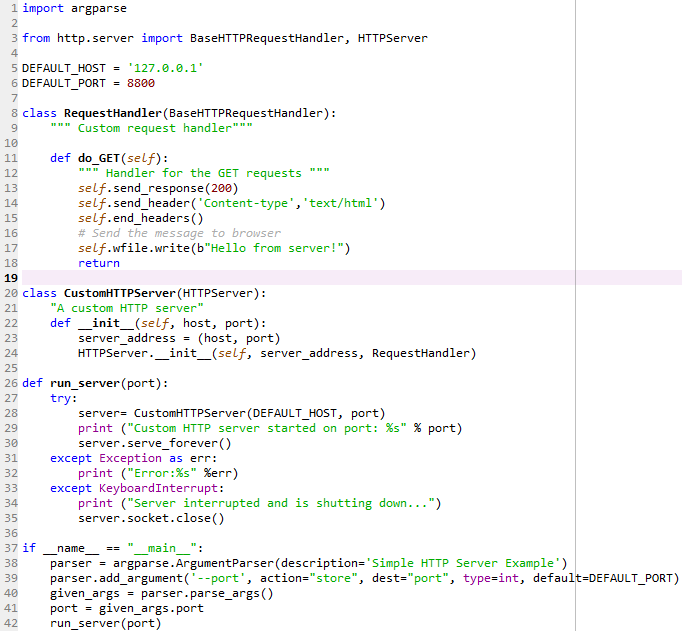
HTTPServerクラスから継承したCustomHTTPServerクラスを作成します。 コンストラクターメソッドでは、CustomHTTPServerクラスが、ユーザー入力として受信したポートを設定します。
コンストラクターには、WebサーバーのRequestHandlerクラスが設定されています。 クライアントが接続されるたびに、サーバーはこのクラスに従って要求を処理します。
RequestHandlerは、クライアントのGETリクエストを処理するアクションを定義します。 write()メソッドを使用して、HTTPヘッダー(コード200)とサーバーからの成功メッセージHelloを送信します。
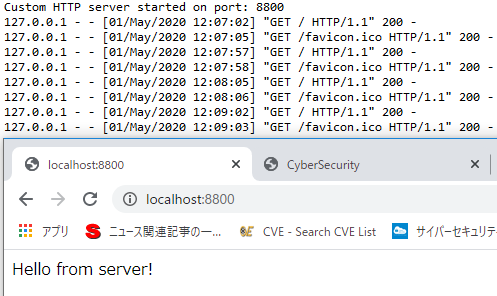
$python3 simple_http_server.py により、ポート8800でHTTP Webサーバーが起動します。ブラウザからこのWebサーバーにアクセスするには、http://localhost:8800と入力します。
プロキシ経由でWebページを閲覧したいとします。 ブラウザにプロキシサーバーを設定する場合の他に、インターネットで利用可能なパブリックプロキシサーバーを使用できます。

Googleまたはその他の検索エンジンで検索すると、無料のプロキシサーバーを見つけることができます。 ここでは(proxy_web_request.py)、デモンストレーションのために150.66.1.137を使用しています。

ソーシャルコード共有サイトhttps://www.github.comにアクセスし、Google検索で公開プロキシサーバーを見つけます。 プロキシアドレス引数がurllibのurlopen()メソッドに渡されました。 プロキシ設定がここで機能することを示すために、応答のHTTPヘッダーを出力します。
HEADリクエストでWebページが存在するかどうかを確認する
HTMLコンテンツをダウンロードせずにWebページの存在を確認したいとします。 これは、ブラウザでget HEADリクエストを送信する必要があることを意味します。 ウィキペディアによると、HEADリクエストは、GETリクエストに対応するレスポンスと同じレスポンスを要求しますが、レスポンスボディはありません。 これは、コンテンツ全体を転送する必要なく、応答ヘッダーに記述されたメタ情報を取得するのに役立ちます。
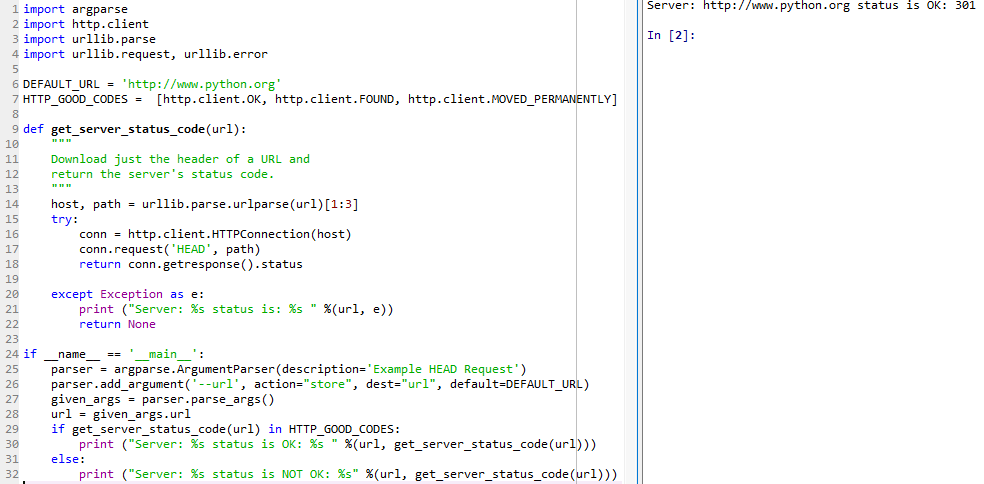
このコードchecking_webpage_with_HEAD_request.pyはHEADリクエストをhttp://www.python.orgに送信します。 これはホームページのコンテンツをダウンロードせず、サーバーが有効な応答(たとえば、OK、FOUND、MOVED
PERMANENTLYなど)を返すかどうかをチェックします。
サーバーにHEADリクエストを送信できるhttplibのHTTPConnection()メソッドを使用しました。 必要に応じてパスを指定できます。
ここで、HTTPConnection()メソッドは、ホームページまたはhttp://www.python.orgのパスをチェックします。
クライアントコードでのMozilla Firefoxのスプーフィング
Pythonコードから、Mozilla Firefoxから閲覧しているようにWebサーバーに見せかけたいとします。
HTTPリクエストヘッダーでカスタムユーザーエージェントの値を送信できます。クライアントコードを使ったMozilla Firefoxのなりすましを次のように実施します(spoof_mozilla_firefox_in_client_code.py)。
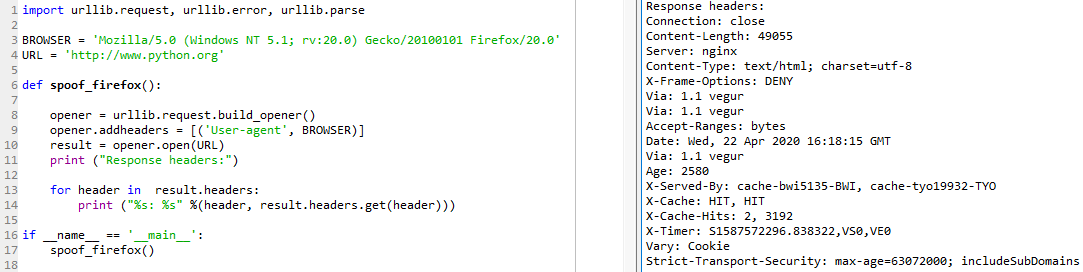
urllib2のbuild_opener()メソッドを使用して、ユーザーエージェント文字列がMozilla / 5.0(Windows NT 5.1; rv:20.0)Gecko / 20100101 Firefox / 20.0)として設定されたカスタムブラウザーを作成しました。
Webサーバーのユーザーは、Webページのダウンロードのパフォーマンスを向上させたいと考えます。 HTTPデータを圧縮することにより、Webコンテンツの提供を高速化できます。
コンテンツをgzip形式に圧縮して提供するWebサーバーを作成してみましょう。 コード(http_compression.py)は、HTTP圧縮を次のように説明しています。
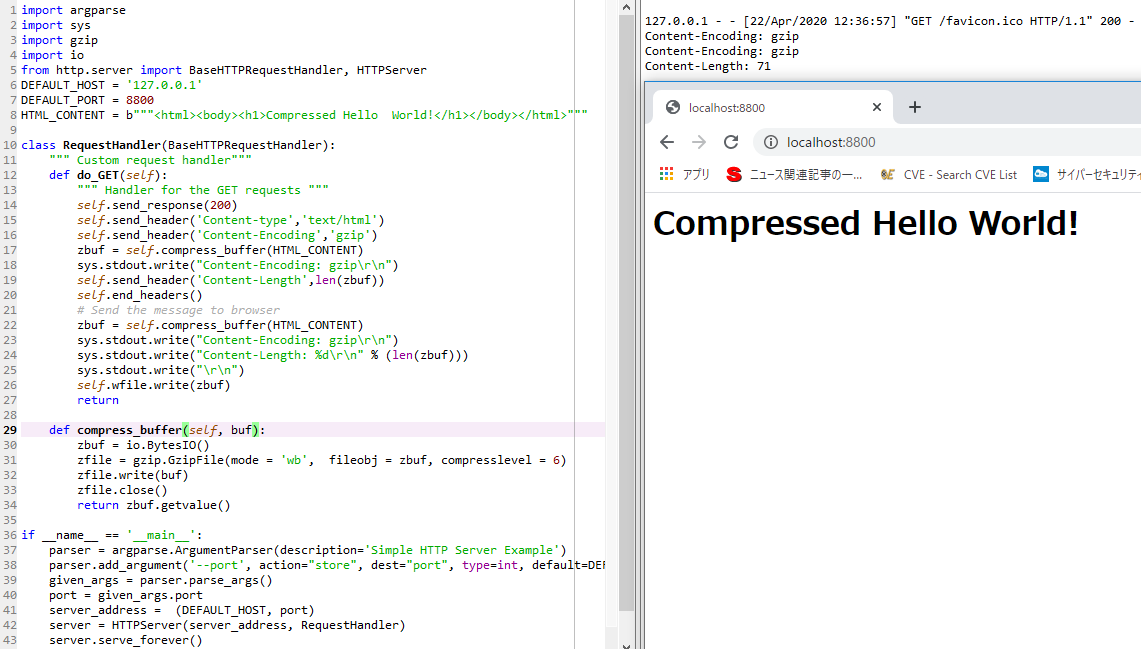
このスクリプトを実行し、 http://localhost:8800にアクセスしたときのブラウザ画面のテキスト(HTTP圧縮の結果)は次の通り:Compressed
Hello World!
BaseHTTPServerモジュールからHTTPServerクラスをインスタンス化してWebサーバーを作成しました。 このサーバーインスタンスにカスタムリクエストハンドラーをアタッチし、compress_buffer()メソッドを使用してすべてのクライアント応答を圧縮します。
定義済みのHTMLコンテンツがクライアントに提供されています。
CGIを使用した(Pythonベースの)Webサーバーのゲストブックの作成
Common Gateway Interface(CGI)は、カスタムスクリプトを使用してWebサーバー出力を生成できるWebプログラミングの標準です。
ユーザーのブラウザーからのHTMLフォーム入力をキャッチし、それを別のページにリダイレクトして、ユーザーの要求を処理します。
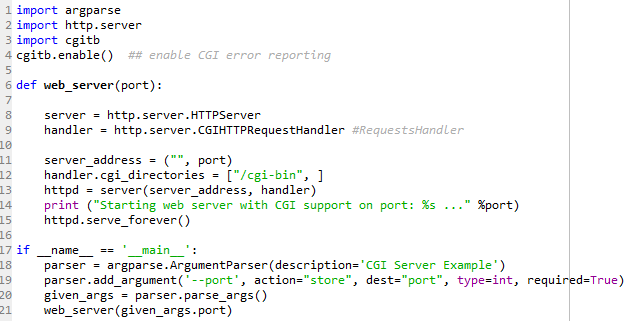
以下はCGIをサポートするWebサーバーcgi_server.pyです。
ファイルcgi_server.pyのあるディレクトリにコメントフォームsend_feedback.htmlを置きます。更に、cgi-binディレクトリを作成(mkdir cgi-bin)し、CGIスクリプトget_feedback.pyをcgi-binディレクトリに置きます。次に、Webサーバーcgi_server.pyを立ち上げます(python3 cgi_server.py --port 8800)。ブラウザからサーバにアクセス(localhost:8800)します。
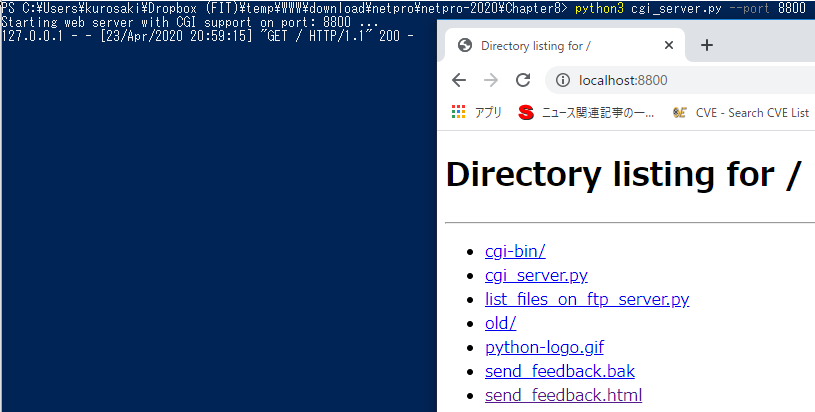
次に、send_feedback.htmlをクリックするとフィードバックフォームを含むHTMLページが表れる。nameとcommentに適当な文字を入れてsubmitすると、WebサーバーがフォームデータをCGIスクリプトに送信し、このスクリプトによって生成された出力がブラウザ上に表示されます。
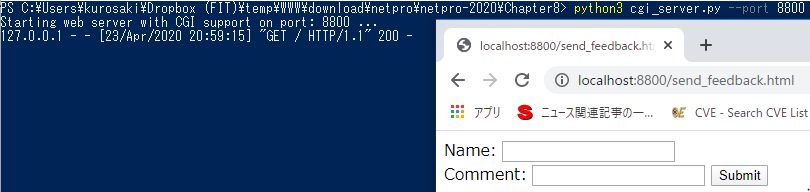
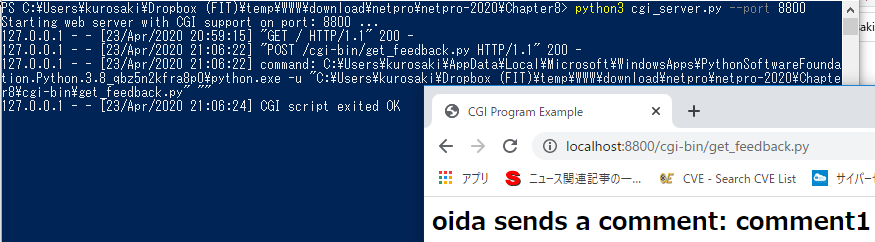
CGIリクエストを処理できる基本的なHTTPサーバーの設定を使用しました。 Python 3は、http.serverモジュールでこれらのインターフェースを提供します。
ハンドラーは、/cgi-binパスを使用してCGIスクリプトを起動するように構成されています。 他のパスを使用してCGIスクリプトを実行することはできません。
send_feedback.htmlにあるHTMLフィードバックフォームは、次のコードを含む非常に基本的なHTMLフォームを示しています。
<html>
<body>
<form action="/cgi-bin/get_feedback.py" method="post">
Name: <input type="text" name="Name"> <br />
Comment: <input type="text" name="Comment" />
<input type="submit" value="Submit" />
</form>
</body>
</html>
フォームメソッドはPOSTであり、アクションは/cgi-bin/get_feedback.pyファイルに設定されていることに注意してください。 このファイルの内容は次のとおりです。
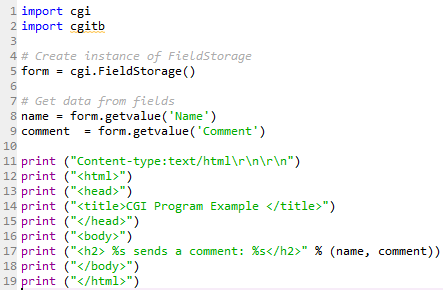
このCGIスクリプトでは、FieldStorage()メソッドがcgilibから呼び出されます。 これは、HTMLフォーム入力を処理するフォームオブジェクトを返します。
ここでは、getvalue()メソッドを使用して、2つの入力(名前とコメント)が解析されます。 最後に、スクリプトは、ユーザーがコメントを送信したという行をエコーバックしてユーザー入力を確認します。
Linuxで次のようなエラーが発生した場合:
127.0.0.1 - - [22/Jun/2017 00:03:51] code 403, message CGI script is not
executable ('/cgi-bin/get_feedback.py')
次のコマンドを実行することで実行可能にできます。
$ chmod a+x cgi-bin/get_feedback.py
実行可能になったら、問題なくプログラムを再実行できます。
コマンドプロンプトを立ち上げ、以下の4つの課題を実施し、その実施結果のスクリーンコピーを貼り付けたレポートを作成し提出する。
1.download_data.pyのREMOTE_SERVER_HOSTに http://www.fit.ac.jpとは異なるurlを設定しdownload_data.pyを実行した結果を報告する。
2.Webサーバーsimple_http_server.pyを立ち上げ、次にdownload_data.pyを使ってWebサーバーをアクセスした結果を報告する。但し、サーバーのポート番号は80にする必要があります。また、クライアントがアクセスするホストはhttp://127.0.0.1にする必要があります。
3.現在利用できるプロキシサーバーをgoogleで検索し、proxy_web_request.pyのPROXY_ADDRESSを書き換えて、proxy_web_request.pyを実行した結果を報告する。
4.checking_webpage_with_HEAD_request.pyを使って、statusコードが異なる2っのurlを見つけ、実行した結果を報告する。